

01
Description
More about
02
Short list of features
More about
03
Technical Description
More about
04
Repositories and Download
More about
AiiDA (Automated Interactive Infrastructure and Database for computational science) is a Python materials’ informatics framework to manage, store, share, and disseminate the workload of high-throughput computational efforts, while providing an ecosystem for materials simulations where complex scientific workflows involving different codes and datasets can be seamlessly implemented, automated and shared.
AiiDA is designed around the four ADES pillars of materials informatics [1] and, complemented by the Materials Cloud website [2], it enables and facilitates compliance with the FAIR Guiding Principles for scientific data management and stewardship. At the low-level, AiiDA takes care of Automation and Data storage for the management and safeguarding of calculations, data and workflows. At the user level, it provides an advanced and intuitive research Environment for accelerating scientific discoveries, and Sharing capabilities to enable collaborative research.
Moreover, while managing the pipelines of simulations, AiiDA keeps track automatically of the full provenance of all data and calculations, guaranteeing reproducibility not only of single calculations, but of full simulation workflows. The provenance is stored in the form of a directed graph in a database, allowing fast and efficient queries by the user.
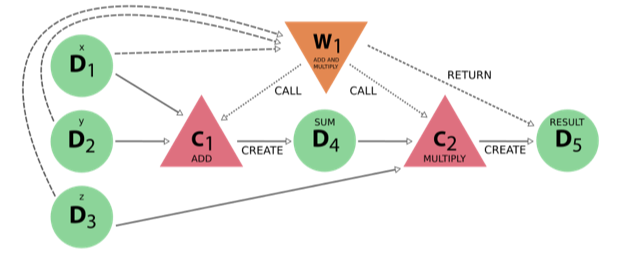
![]()
The figure on the left shows the schematic representation of a very simple toy-model workflow that consists of taking 3 input numbers and performing two processing steps (adding two of them first, and then multiplying the result by the third one). The figure on the right shows the same types of connectivity (in a different style) but for a real high-throughput study, consisting of thousands of advanced workflows and calculations.
AiiDA is designed with a plugin interface, supporting many different types of data and simulation codes (including all the MAX flagship codes). The list of existing plugins for AiiDA can be found on the AiiDA plugin registry.
Performance as HTC platform
AiiDA is designed to run high-throughput jobs, each of them ranging from small post-processing steps to very large HPC jobs scaling on thousands of nodes on large supercomputers. As such, the combination of the automation and high-throughput capabilities of AiiDA with the optimised performance of the MAX HPC simulation codes makes it possible to efficiently use pre-exascale and exascale machines for the simulation of advanced materials properties.
After the latest re-design of the engine [3,4] AiiDA has proven capable of handling tens of thousands of simultaneous calculations. This was demonstrated during the “LUMI hero run”: an extreme high-throughput test that was possible thanks to being granted exclusive access to one of Europe’s newest pre-exascale infrastructures [5]. During these, AiiDA managed to orchestrate over 55,000 Quantum ESPRESSO calculations to optimize the geometry of more than 15,000 inorganic compounds, completely filling the full supercomputer for 12 hours (corresponding to a record number of Epyc cores exceeding the 196,000).
![]()
References
[1] G. Pizzi et al. Comp. Mat. Sci. 111, 218-230 (2016)
[2] https://www.materialscloud.org/
[3] S.P. Huber et al., Scientific Data 7, 300 (2020)
[4] M. Uhrin et al., Comp. Mat. Sci. 187 (2021)
[5] https://www.lumi-supercomputer.eu/about-lumi/
AiiDA aims to help researchers with managing the complex workflows of high-throughput research and making their results fully reproducible. It does so by providing the following key features:
-
Workflows: Write complex, auto-documenting workflows in python, managing both simple user-defined functions and external executables on local or remote computers. The AiiDA workflow engine enables users to encode their workflow logic in functional building blocks and combine them in sophisticated simulations. The event-based engine can deal with demanding high-throughput workloads, supporting tens of thousands of processes per hour with full checkpointing.
-
Data provenance: Automatically track inputs, outputs & metadata of all calculations and data in a provenance graph for full reproducibility, which means being able to reconstruct the complete history of each calculation or scientific result. Perform fast queries on graphs containing millions of nodes.
-
HPC interface: Move your calculations to a different computer by changing one line of code. AiiDA is compatible with many schedulers, including SLURM, PBS Pro, torque, SGE or LSF. The daemon prepares the necessary input files, sends them to the cluster, submits a new job to the scheduler, and continues monitoring the status of calculations, retrieving and parsing the relevant files as soon as the job finishes.
-
Plugin interface: Extend AiiDA with plugins for new simulation codes (input generation & parsing), data types, schedulers, transport modes and more. The public AiiDA registry is the central place to find AiiDA plugins, listing plugins, authors, installation instructions and which extensions they provide.
-
Open Science: Export subsets of your provenance graph and share them with peers or make them available online for everyone on the Materials Cloud. When uploaded to this platform, peers can browse the graph interactively, download individual files or the whole database, and start their research right from where the original author left off.
Open source: AiiDA is developed publicly on the aiida-core GitHub repository and is released under the MIT open source license, making it suitable for use both in academic and commercial settings. We are strong supporters of open source software; nevertheless, AiiDA plugins can connect both to open source and commercial codes, and plugin developers can make the choice to develop their plugin privately or under different licenses if they want to.
AiiDA is an open-source Python infrastructure to help researchers with automating, managing, persisting, sharing and reproducing the complex workflows associated with modern computational science and all associated data
DATA STORAGE AND QUERYING
By default, data are stored both in a file repository and in a PostgreSQL database for efficient querying. The data does not only contain the raw and parsed inputs and outputs, but also the whole provenance graph. Sharing is enabled by export functionalities to export the full provenance graph or parts of it in the form of archive files, and then reimport it in a different AiiDA instance.
The directed graph is stored in the SQL database; AiiDA provides a QueryBuilder engine to express general graph queries with filtering and projections in a simple and uniform python-like syntax, without the need to know SQL or the underlying design of the database. The AiiDA ORM leverages the SQLAlchemy python ORM for the connection to the PostgreSQL database.
Moreover, the data management backend has been completely abstracted and modularized in the last major 2.0 release. This means not only that exported archive files can now be accessed and explored directly without needing to import them into AiiDA first, but also that the backend classes can be extended and alternatives to the default file repository + PostgreSQL could be developed in the future (for example, to use remote resources such as cloud object stores).
ENGINE
AiiDA defines a rich and powerful workflow language that allows declarative definition of inputs, outputs, error codes and the outline of the code, making it self-documenting, and enabling automatic input and output validation and automatic documentation generation features. In addition, AiiDA provides python decorators that make it straightforward, by just adding one line of code, to convert any python function (used e.g. for pre- or post-processing) into an AiiDA process, that gets automatically tracked in the AiiDA provenance graph along with links to its inputs and outputs.
The engine that automates the simulations and the workflows is based on an event queue (using RabbitMQ as the queue manager) to enable "real-time" instantaneous reaction to events, like submission or completion of a calculation. It is also empowered by advanced algorithms to provide sustained throughput on HPC resources with automatic rate-limiting and batching of connections to avoid overloading. Additional algorithms ensure robustness to downtimes and temporary failures, with an exponential backoff mechanism and the possibility to pause and restart any process.
The engine is run by a multi-slot, multi-process daemon managed via the Circus python library. Control of the workflow is maintained centrally, allowing for stopping and restarting/rebooting the AiiDA server without any data loss; the engine will pick up the workflow and continue execution from where it was left off (while e.g. simulations continue to run on HPC supercomputers).